
Attention Visualization in Text Classification
2019-04-25
This post will give an brief introduction of attention mechanism in seq2seq model and then show you how does the attention work in text classification. Finally we visualize the attention weights in a RNN based text classification model. The model is implemented in Keras.
Ref:
Thanks the above 2 wonderful works.
1. About attention
Attention first comes from the way human beings observing things. Our brains use visual attention mechanism to process the visual information we received. When observing a picture, we first have an quick overview, and then our attention focus on several particular parts to gain the information we want further.
Except for the computer vision application, attention mechanism is useful in many NLP tasks too. Such as machine translation and text classification. You may be familiar with the model seq2seq + attention which is wellknown in machine translation, which is shown below. Among which the $a(s_{t-1}, hj)$ is a function for computing the correlation between decoder state $s{t-1}$ and each encoder state $h_j$.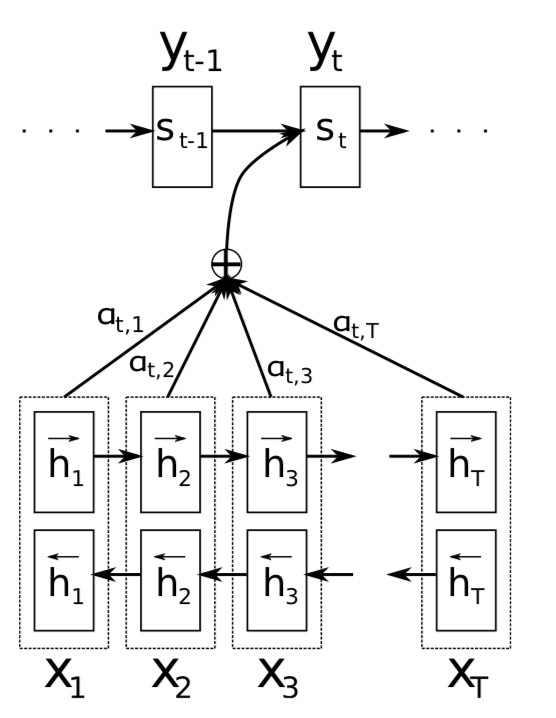
The attention mechanism’s expression are as follows: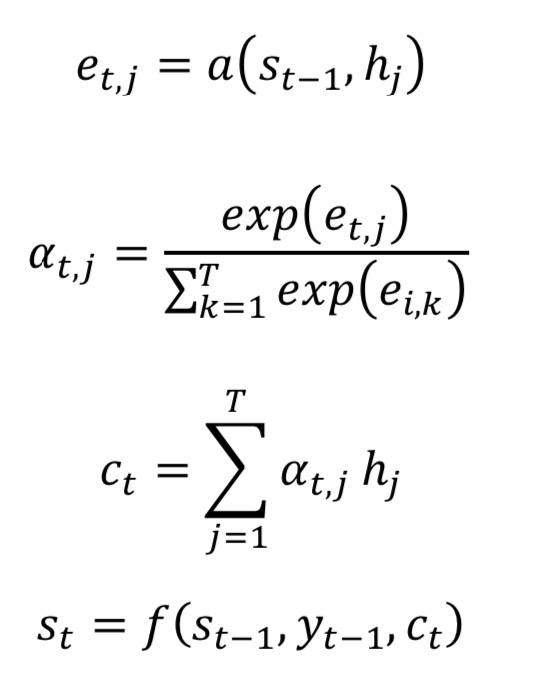
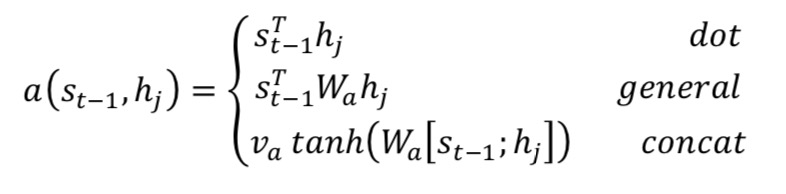
2. Attention in text classification
For the case of text classification, since only 1 label is asked to be output, we don’t have a decoder, neither do the decoder state. So the correlation function $a(s_{t-1}, h_j)$ is changed to $a(h_j)$ for computing the correlation between the label and each encoder state $h_j$. For the details of function $a(⋅)$ and the function $a_j = max(e_j)$ which only keeps the most significant correlation value, you can design them by your need. And the attention weights represents the relationship between the output label and the input tokens.
$$ e_j = a(h_j) $$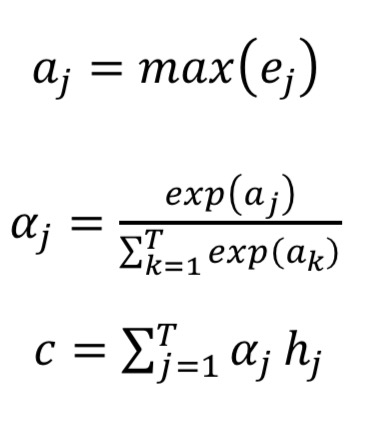
3. Visualize attention weights
This section will introduce you how to visualize the attention weights in a text classification task.
In this procedure, we need to get the words and their corresponding attention wgts and the final output label. The final effect will looks like this.
The main steps are as follows.
- Train a usual text classification model(mdl) and save its model wgts.(using checkpoints)
- The attention layer (better designed as an independent class) has a switch to control output probs or output attn wgts.
- Build 2 models and load the saved model wgts. One for predict the label(pred_mdl), the other for get the attention wgts(attn_mdl).
First we provide you an implementation of Attention layer with such switch.1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374# -*- coding: utf-8 -*-"""File: attnlayer.pyDate: 2019-03-30 15:46Author: amy"""import loggingfrom keras import initializers, layersfrom keras.engine import InputSpec, Layerfrom keras.utils import normalizefrom keras import backend as Kimport config as conflogger = logging.getLogger("console_file")class AttentionWeightedAverage(Layer):"""Computes a weighted average of the different channels across timesteps.Uses 1 parameter pr. channel to compute the attention value for a single timestep."""def __init__(self, return_attention=False, **kwargs):self.init = initializers.get('glorot_uniform')# the swith to control return valuesself.return_attention = return_attentionsuper(AttentionWeightedAverage, self).__init__(**kwargs)def get_config(self):config = {'return_attention': self.return_attention,}base_config = super(AttentionWeightedAverage, self).get_config()return dict(list(base_config.items()) + list(config.items()))def build(self, input_shape):''' define your attention layer params here: '''self.input_spec = [InputSpec(ndim=3)]assert len(input_shape) == 3self.W = self.add_weight(name="Wa",shape=(input_shape[-1], conf.n_classes),initializer=self.init,trainable=True)self.trainable_weights = [self.W]super(AttentionWeightedAverage, self).build(input_shape)def call(self, x):''' define your attention function here: '''ej = a(hj) # implement it by yourself.# find the most important value# ai: (n_classes, 1)ai = K.max(ej, axis=-1)# softmax to get the attention weightsatt_weights = layers.Softmax(axis=-1)(ai)# weight-avg xweighted_inputs = x * K.expand_dims(att_weights)# output probs for each classresult = K.sum(weighted_inputs, axis=1)if self.return_attention:# return both attn output and attn wgts (attn scores for each class)return [result, att_weights]# only return attn layer output: wgted avg hidden statedsreturn resultdef get_output_shape_for(self, input_shape):return self.compute_output_shape(input_shape)def compute_output_shape(self, input_shape):output_len = input_shape[2]if self.return_attention:return [(input_shape[0], output_len), (input_shape[0], input_shape[1])]return input_shape[0], output_len
Second, we provide you a RNN model using the predefined attention layer.
Finally, we will show you how to gain and visualize attn wgts.
By the way, after getting the words, prediction label and the attention weights, you can draw the above picture in differenent ways. The larger the attention weight is, the darker the text background color should be.