
Bloom Filter
2018-08-05
This article will show you what is Bloom Filter (BF for short) and when should we use it. And a python3 implementation of Bloom Filter is shown. Thanks for this article in geeksforgeeks.
What is BF?
Bloom Filter is useful when you want to check whether an element exists in a set. It’s an space-efficient probabilistic data structure, which makes the check quick and only occupies little memory especially when your set is too large to load in memory.
For example, you’re registering a new username, and the server has to check whether your input username is occupied. Since the username set can be very large, so a linear finding algorithm is too slow. And a binary search is also not that efficient. But BF can do it in constant time complexity.
How to build a BF?
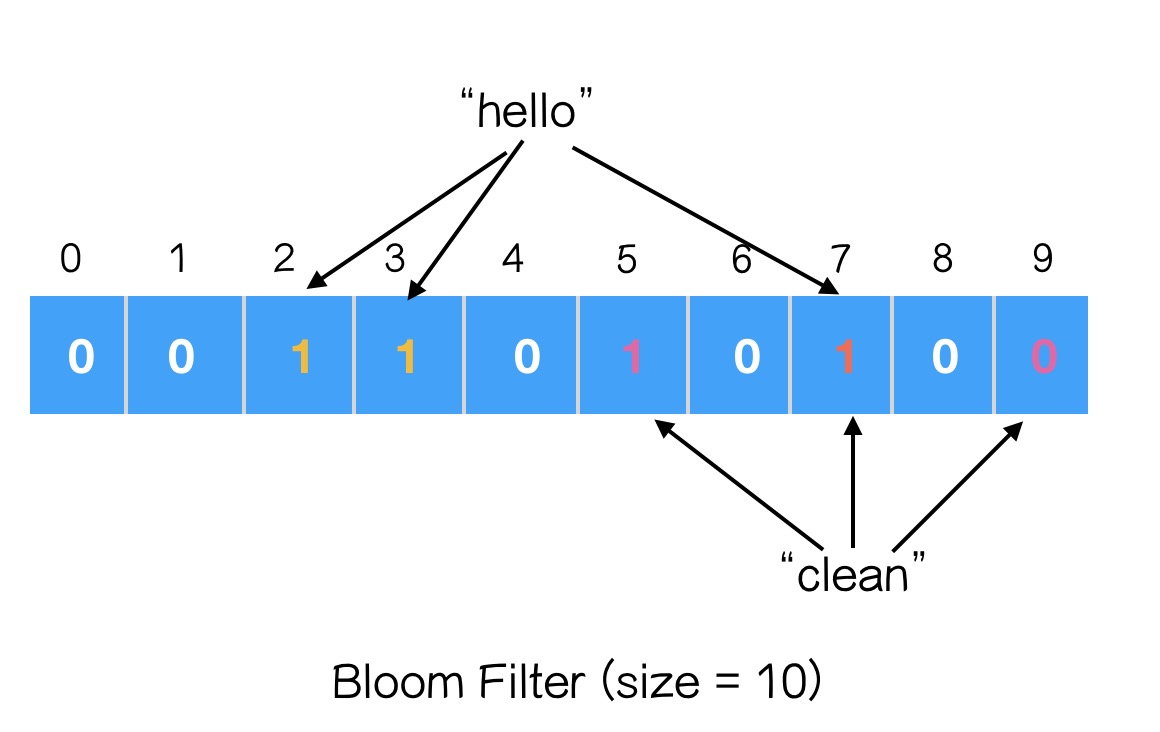
- Create BF:
create a bit array with size: N, and initialized with 0s. Add an new element to BF:
there are k different hash functions: h1(·), h2(·), … hk(·)
bit_1 = h1(x) % N
bit_2 = h2(x) % N
…
bit_k = hk(x) % N
and set bit_1, bit_2, … bit_k to 1 in the bit array.Check a element exists in BF:
repeat step 2: compute bit_1, … bit_k and check whether these bits are all set to 1 in bit array, if Yes then return True.
False Positive Error:
A collision may occur in BF. For example, “near” corresponds to [1,4,5] bits in BF, “going” corresponds to [2,3,5] bits in BF, when we want to check whethe “enjoy” is in BF. We compute the hashes and got [1, 2, 5], we check the BF and found these bits are all 1s, so we return True. But actually “enjoy” is not in our set. This is called False Positive result. e.g. A username is not in the set but BF said it is. And BF will never make False Negative error, that is, telling you an in-set username is not in the set.
Key points to BF:
- You can lower False Positive rate by taking more space and computing more hash funcs.
- The hash functions need to be independent and uniformly distributed so that the collision probability won’t be high.
- Given the set element num $n$ and your expected FP error rate $p$, the Bloom Filter’s array size $m$ and hash functions’s num $k$ can be estimated.
$$m = -\frac{nlnp}{(ln2)^2}$$
$$k = \frac{m}{n}ln2$$ - Given the bf size $m$ and hash function num $k$, the FP rate can be estimated.
$$p = [1 - (1 - \frac{1}{m})^{kn}]^k \approx (1 - e^{-kn/m})^k $$
Implementation of Bloom Filter:
|
|
Output is: