
xpath那些事儿
2017-05-03
今天让我们来聊聊Xpath!Xpath在web爬虫中使用的非常频繁,它能够帮助我们方便地定位到网页中的某个(些)具体元素。
本文的主要目的是记录一些xpath的常用知识,捋一捋学习的的思路。
提纲:
1.何为Xpath?
2.通过例子学习:
3.selenium中使用find_element_by_xpath()定位元素:
1. 何为Xpath?
Xpath,从它的姓,我们可以知道它和XML有些关系。XML指可扩展标记语言(EXtensible Markup Language)
直观地感受一下XML语言表示出的文档的样子:
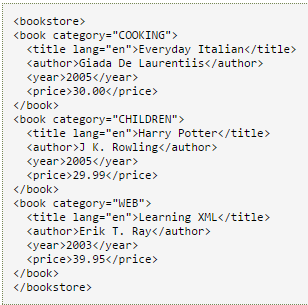
图1-XML 示例
可以发现:XML文档层级清晰,父节点包着子节点。当我们要定位到其中的某一个节点时,可以从某个祖先节点开始,沿途经过某些节点到达目标节点,这就构成了一条路径,许许多多这样的路径生发出来,看起来就像一棵倒置的大树,根节点在上,叶子节点在下。
Xpath就是这类路径的表示方法(路径表达式)。Xpath不仅适用于XML文档,html文档它也搞得定!
2. 通过例子学习:
- Xpath的教程和参考手册:W3C school–XPATH里面包含了详细的语法知识和例子。
- 推荐Chrome的Xpath Helper扩展,会随当前网页自动加载,输入xpath会自动显示出定位的元素。
- 如果想知道某个元素的xpath,可以使用chrome debugger的copy xpath功能,那里的xpath表达式简洁易懂。
下面展示了一些有用的例子,以后可能会用到。
选取 class = ‘u ‘的 div:
1/html/body/div[@class='ut']选取 table 元素的某个部分, 索引下标从1开始:
1/html/body/div[@class='ut']/table/tbody/tr/td[2]选取 id = ‘login ‘的 div:id是唯一的;//表示可以不从根节点开始搜索,只要满足表达式即可;/表示从根结点开始搜索
1//div[@id='login']选取 id = ‘login ‘的 元素,由于id是唯一的,所以也可以不指明div:
1//*[@id='login']当满足条件的元素有多个时,只选择最后一个:
1/html/body/div[@class='ut']/div/span[last()]复合谓词 and:选取具有某个子元素的父节点div:
1/html/body/div[@class='ut' and ./div/span[@class='uu']]函数 not:排除具有某个子元素的父节点div, 轴:following-sibling,可以定义相对于当前结点的节点集合;./:以当前结点为根搜索
1/html/body/div[@class='ut' and not(./div/span[@class='uu']) and following-sibling::div[@class='mm']]选取 文本内容包含”hello”的 span:
1/html/body/div/span[contains(text(),'hello')]选取 文本内容以”hello”开头的 span:
1/html/body/div/span[starts-with(text(),'hello')]
3. selenium中使用find_element_by_xpath()定位元素:
基本用法:
1234# 获取div元素div_ele = driver.find_element_by_xpath("/html/body/div[@class='ut']")# 获取div中的文本div_content = div_ele.texttext()函数无法使用
123# 试图获取某text()元素div_ele = driver.find_element_by_xpath("/node/text()[2]")# 注意!这样会报错,因为find_element_by_xpath()返回的必须是element类型,而不是str!只能选择class属性为一个的情况:
1div_ele = driver.find_element_by_xpath("/node/div[@class='u']")选择具有多个class属性的元素,可以用css selector:
1<li class='ok good nice'>1div_ele = driver.find_element(By.CSS_SELECTOR, 'li.ok.good.nice')